Artificial Meaning
Ahan R
The question of whether Machines Can Think . . . is about as relevant as the question of whether Submarines Can Swim.
'Dumb' Meaning
This post isHannes Bajohr. Dumb Meaning a reply to Bajohrs "Dumb Meaning: Machine Learning and Artificial Semantics". Bajohr argues two main points:
- Neural nets (especially modern large language models (LLMs) are capable of “dumb meaning
- Multimodal” (being able to process different “types of data”. E.G. Text, video, sound) capabilities of certain neural networks imply a level of grounded meaning
In asserting the first point Bajohr puts forward his category of “gradated” meaning. This is a conception of semantics which "no longer presupposes a mind" Ibid., 62. He explains that the “human-like” text of neural networks could be traced to them occupying a spot on this spectrum of “gradated meaning”. Specifically, “dumb” is defined as a lower level of “broad meaning”, which requires “embodied intelligence, cultural and social background knowledge, or the world- disclosing function of language”. It can be defined as an “effect of correlations.” Ibid., 62
Bajohr’s second point is that by relating text data to image data, neural networks could possibly escape Harlands “Symbol Grounding Problem” Stevan Harnad. The Symbol Grounding Problem. and archieve a “second degree of dumb meaning” Bajohr "Dumb Meaning", 66. These types of neural networks are classified as “multimodal” and contain “conceptual” neurons that fire for both the text of a thing and its visual representation. For example, the text ‘teapot’ and a painting of a teapot.
Bajohr’s first point relies on LLMs capturing “latent correlations between signs”Ibid., 63 as proof that it is privy to some level of meaning. In his view, neural networks can now encode both “the correlations of words to words but also correlations of correlations”. The effect of which allows it to express certain semantic relations through vector Mikolov et al. Efficient Estimation of Word Representations in Vector Space representations. These representations are expressed in an n-dimensional vector space and have the ability to capture “syntactic and semantic regularities in language”Ibid
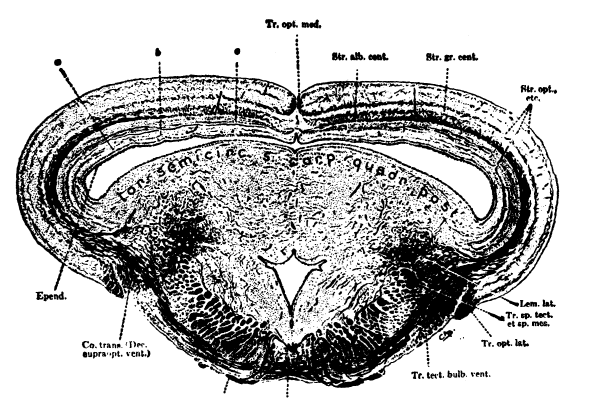 Ariens-Kapper's cross-section of the frogs brain through the
collicuiusThis phenomenon of implicit patterns being encoded spatially is
unsurprising given the history of neural network systems. The development of the artificial neuron was inspired by research concerning
the frog’s retina. Starting from an observation that the optical nerves
in animals contain fewer receptors than the retina itself - scientists
were able to map out the functionality of how signals were transferred from the brain to eye. They measured stimuli response while introducing different visual phenomena into the frogs field of vision.
Concluding that the eye already performs basic pattern
recognition before any information is sent to the brain.
Ariens-Kapper's cross-section of the frogs brain through the
collicuiusThis phenomenon of implicit patterns being encoded spatially is
unsurprising given the history of neural network systems. The development of the artificial neuron was inspired by research concerning
the frog’s retina. Starting from an observation that the optical nerves
in animals contain fewer receptors than the retina itself - scientists
were able to map out the functionality of how signals were transferred from the brain to eye. They measured stimuli response while introducing different visual phenomena into the frogs field of vision.
Concluding that the eye already performs basic pattern
recognition before any information is sent to the brain.
By transforming the image from a space of simple discrete points to a congruent space where each equivalent point is described by the intersection of particular qualities in its neighborhood, we can then give the image in terms of distributions of combinations of those qualities. In short, every point is seen in definite contexts. The character of these contexts, genetically built in, is the physiological synthetic a priori.
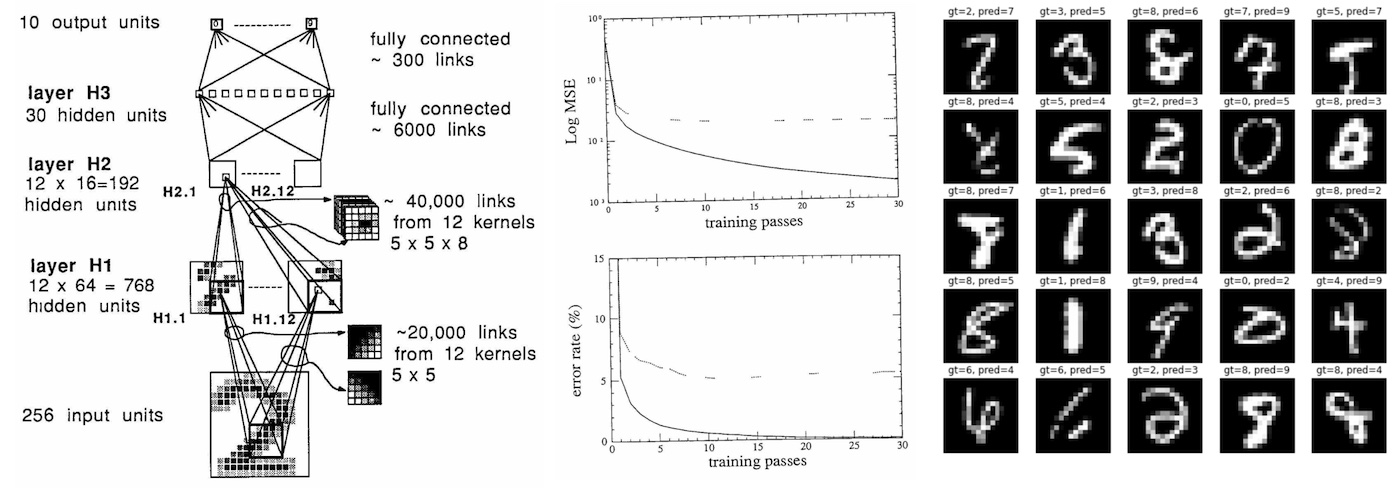
This concept was extended in “A logical calculus of the ideas immanent in nervous activity”. W. S. McCulloch and W. Pitts. A Logical Calculus of The Ideas Immanent in Nervous Activity. The first paper to propose the concept of an artificial neuron, on which neural networks were later built. The history of all machine learning starts with a replication of pattern recognition. This, in combination with the Hebbian principle of “Neurons that fire together, wire together” gave rise to the first neural networks. Structures that encode patterns.
Frank Rosenblatt’s Perceptron is the prototypical example of this capability. Given a matrix of 20 x 20 photoreceptors and a layered structure of artificial neurons, the machine can produce an output of 0 or 1 if a given image is recognized. Information within the perceptron is encoded within a layered structure and manipulated through math.
A large part of early research within neural network development was calculating the distance between points and performing geometrical calculations in order to mimic perception. The consequence of which was producing structures that encode patterns of data spatially. Given this functionality of the earliest neural networks, as machines that recognize patterns, M. Pasquinelli. The Eye of the Master: A Social History of Artificial Intelligence it’s expected that text data would also follow this rule. The same objection can be made against Bajohr’s second point.
The nature of multimodal networks requires a conversion into a single type of data. Each data type (modality) is first processed by specialized networks (e.g., CNNs for images, RNNs for text, or spectrograms for audio) to extract features. These features are then mapped into a common embedding space, often through techniques like shared embedding layers or cross-modal learning. The network learns to project all modalities into this unified space, where each type of data is represented as a vector or matrix of numbers, making it possible to compare information. Ngiam et al. Multimodal Deep Learning.
Multimodal networks are not finding correlations between completely different domains. Instead, all information is converted into a single type of data, which is processed by the network.
Despite the flaws with Bajohr’s argument, he raises the interesting observation that LLMs
are able to produce apparently situational understanding, as LaMDA did, without ever being ’in a situation'.
Being in a situation requires embodied knowledge of the world, which LLMs do not posses. However, they’re very persuasive in their ability to convince people that they do. Their text is human-like enough to elicit accusations of ’sentience’ and ’consciousness’. Why is it that LLMs seem to have situational understanding?
Artificial Language
If a machine is expected to be infallible, it cannot also be intelligent.
In 1677, John Peters published “artificial versifying or, the school-boy’s recreation. a new way to make latin verses”. His treatise laid out instructions in constructing “hundreds of hex- ameter verses” even if one “understands not one word of Latin” and “only knows the A.B.C. and can Count to 9” John Peters. Artificial versifying or, The school-boy’s recreation. A new way to make Latin verses.
He provides 6 grids of letters (which he named "The Versifying Ta- bles"), each linked to a digit in a 6-digit number (e.g., 172912). For each digit, use the corresponding grid to locate the starting position, count to the 9th letter, and note it down as the first letter of the word. Continue counting every 9th letter across rows until a black square ends the word. You repeat this process for all six digits, combining the resulting words to form a line of Latin hexameter verse.
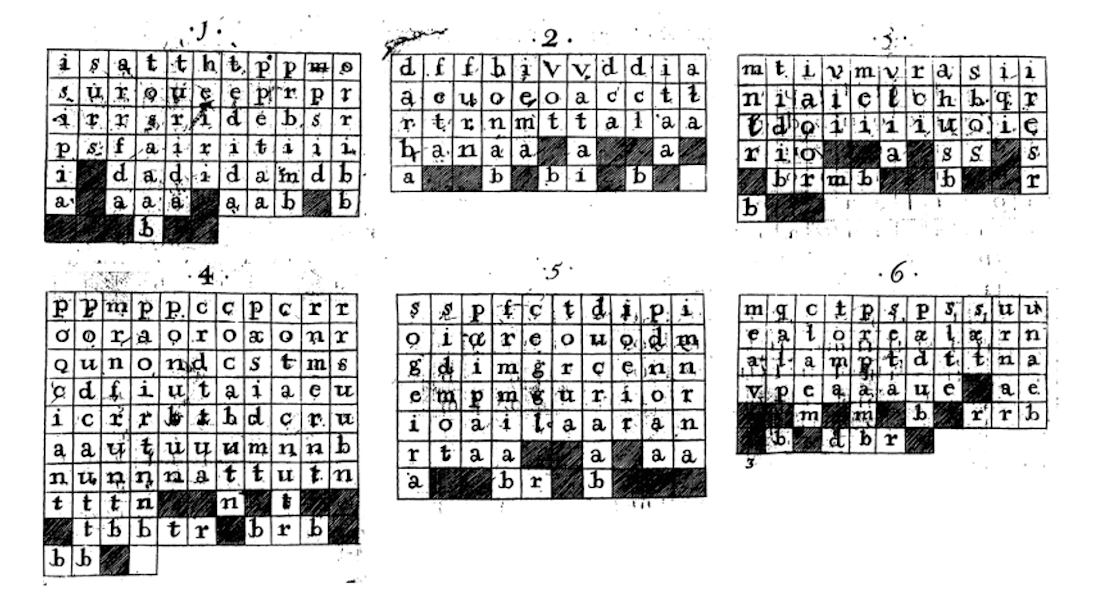
Despite the confusing presentation, each table secretly hides 9 words that are found through counting. The tables are ordered as to obey Latin grammar and will eventually produce a verse that follows dactylic hexameter The type of meter used in both Greek and Roman epic poetry. When all steps have been followed, you end up with a line similar to this:
“turbida ella malis producunt pignora tantum.”
For the evil, messy wars create only promises.
Not necessarily the most original verse, but an understandable one. In constructing his method, John Peters laid out a pattern for language. Specifically, that of adjective noun adverb verb noun adjective23. This, in conjunction with a specific word-list, allowed Unlike English metrical poetry, which requires stressed and unstressed syllables. Latin poetry only requires words that end with either a short or long vowel. By scheduling long and short syllables to follow each other, the hexameter automatically takes shape for the creation of grammatically correct verse without any understanding of its content.
Nearly 200 years later, John Clark followed the method laid out by Peters in producing his machine “The Eureka”. Approximately the size of a modern dishwasher. He reported that, through an interlocking process of turning drums, "The Eureka" was able to produce one  Spokes in the Eureka Machineverse per minute. Words were encoded on rows of stop wire on which wooden staves with printed letters were dropped. As the drums rotated, the staves would align with the stop wires, displaying the appropriate letters through windows on the machine's front, constructing the verse word by word.
Spokes in the Eureka Machineverse per minute. Words were encoded on rows of stop wire on which wooden staves with printed letters were dropped. As the drums rotated, the staves would align with the stop wires, displaying the appropriate letters through windows on the machine's front, constructing the verse word by word.

Despite the varying quality of the generated verses, audiences were enamored with the device. It single-handedly retired Clark after being put on public display at the "Egyptian Hall". A venue that displayed an array of "mechanical curiosities"Jason David Hall. Popular prosody: Spectacle and the politics of victorian versification. According to Clark, the printed Latin verse was “conceived in the mind of the machine”. It was the mechanical expression of an algorithm that encoded a certain pattern of language. Victorian audiences were able to make sense of most of the outputs created by The Eureka. Reporters who witnessed the mechanism wrote that it produced "uncannily well-wrought classical prosody to the masses".
To many, this seems like a primitive precursor to later generative-AI tools. This machine took in an algorithm, expressed those instructions through a physical medium, and produced an output that was seen as meaningful. It utilized a pattern of language (encoded as a set of instructions) in order to produce statements which, when viewed by Victorian audiences, seemed meaningful.
The machine was so successful because it captured and replicated a certain pattern of languageMirchandani et al. Large language models as general pattern machines, 2023. . The Eureka Machine and ChatGPT both don't have any knowledge of the world. This lack of world knowledge can be demonstrated with the Winograd Schema Challenge. If you ask GPT-3 the question, "The trophy doesn’t fit in the brown suitcase because it’s too big. What is too big?". It will answer both "the suitcase" & "the trophy" with equal frequency However, the datasets they both utilize are grounded in the real world. After being provided this (heavily curated) data, they both organize that information using their respective methods.
Similar to the Eureka machine, ChatGPT notices certain structural patterns within statements. For example, a certain subject (Argentina) with a predicate (won the world cup). Once this structure has been established, ChatGPT starts assigning specific vectors to words. Similar words are grouped together, which allows ChatGPT to use them as synonyms when filling in certain types of sentences. This results in ChatGPT having a structure of language that is related to certain vectorspaces of words. The latter being used to fill in the former.

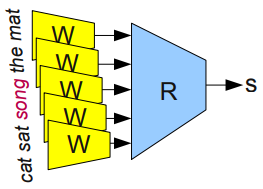
Network for a valid 5 word
statement.
Bottou, 2011 We can demonstrate this by training a network to produce a valid
5-word statement (e.g. cat sat on the mat). The network will have two
parts, one that produces statements and another that checks the validity of these statements.
In attempting to construct a valid statement, the network will notice the structure of the statement and categorize the role of each word using its classifier. When constructing a valid 5-word statement, it'll draw from the vector space it's created and replace the words that have suitable replacements (those that have the least distance to another vector, implying similarity). For example, 'cat' with 'dog'. The pattern of language has been captured and can now be filled in as a template. 
Network classifier
Bottou, 2011
r(w(“cat"), w(“sat"), w(“on"), w(“the"), w(“mat")) = 1
r(w(“cat"), w(“sat"), w(“song"), w(“the"), w(“mat")) = 0
r(w(“dog"), w(“sat"), w(“on"), w(“the"), w(“mat")) = 1Language as a pattern was demonstrated long before the emergence of LLMs. Rubenstein and Goodenough Herbert Rubenstein and John B.Goodenough. Contextual Correlates of Synonymy. argued that “the proportion of words common to the contexts of word A and to the contexts of word B is a function of the degree to which A and B are similar in meaning” For instance, "cat" and "kitten" often share contexts like "pet," "meow," or "cute," suggesting a degree of semantic similarity. . Their findings indicated a strong correlation between the degree of contextual overlap and the perceived similarity of word meanings. A consequence of this is that similar words could be substituted with little change to the overall meaning of a statement.
Language as a pattern emerges from its use. Saussure gives his account in his distinction between langue and parole. Langue is the fixed set of grammatical rules and social conventions that are followed by a community of speakers. Parole is the subjective, individual act of speaking. Parole modifies langue through its expression, and langue informs the articulation of parole.
Parole is exercised without any reference to langue. It is subconscious. In a sense, speech (and writing by extension) unfolds into meaning. In doing so we replicate certain structures of language we have been taught through conversation. We draw on these general structures in order to shape our speaking.
An example of language based solely on frequency can be demonstrated through a simple Markov chain Code is taken from Ben Hoyts blog.. This algorithm works by taking in an input, recording pairs, and noting down a list of possible words that occur after this. These pairs of words are called bigrams, a changeable option of the program - you could choose to record three's or fours. Below is the python implementation:
import collections, random, sys, textwrap
# Build possibles table indexed by pair of prefix words (w1, w2)
w1 = w2 = ''
possibles = collections.defaultdict(list)
for line in sys.stdin:
for word in line.split():
possibles[w1, w2].append(word)
w1, w2 = w2, word
# Avoid empty possibles lists at end of input
possibles[w1, w2].append('')
possibles[w2, ''].append('')
# Generate randomized output (start with a random capitalized prefix)
w1, w2 = random.choice([k for k in possibles if k[0][:1].isupper()])
output = [w1, w2]
for _ in range(int(sys.argv[1])):
word = random.choice(possibles[w1, w2])
output.append(word)
w1, w2 = w2, word
# Print output wrapped to 70 columns
print(textwrap.fill(' '.join(output)))As you may have guessed, the output is mostly nonsense. This is because our program is only recording frequency and pays no mind to the patterns inherent within language. Here is an output using the 10 commandments.
Thou shalt not bear false witness against thy neighbour.
Thou shalt not commit adultery. Thou shalt not steal.
Thou shalt not covet thy neighbours house, thou shalt not commit adultery.
Thou shalt not covet thy neighbours house, thou shalt not steal. Thou shalt not commit adultery.
Thou shalt not steal. Thou shalt not covet thy neighboursWhen an LLM replicates these patterns, all meaning is attributed by the human agent. The model references objects we have experience with, even if they produce a statement that's grammatically unsound, we can still 'make sense' of it. For example, "The cat the dog chased ate killed rat". There is still some meaning evoked through this statement despite it being nonsense. That's because we can relate certain words to our grounded experience and "fill in the blanks". Through our embodied experience of the world, we know that cats eat mice. The sequential occurrence of cat, mice, chased, and killed implies something. It gives us room to derive meaning and speculate on a possible state of affairs. Words alone, due to their occurrence with other words, provide a pattern we can project onto the world.
Humans are especially good at ascribing meaning to things. Not just text, we've attributed agency to geometric shapes moving in certain patterns Fritz Heider and Marianne Simmel. An Experimental Study of Apparent Behavior. . Our ability to derive substantial meaning from words alone is a consequence of language not being a clear communication system. It requires a degree of effort from the interpreter in order to produce the phenomenon of "meaning" Anne C. Reboul. Why language
really is not a communication system:
a cognitive view of language evolution. Most information is delivered non-linguistically. Through social customs and patterns of interaction. Text is a single medium of information delivery that requires us to 'make sense' of it because it lacks these other features. On a similar note. The background knowledge a person has on a topic is actually the key determinant of if they can comprehend text relating to that topic. Signifying that semantic contexts, rather than merely providing topic information, are essential for meaningful processing of written text.
Bransford, John D., and Marcia K. Johnson. Contextual Prerequisites for Understanding: Some Investigations of Comprehension and Recall.
LLMs are able to seem meaningful because they specialize in manipulating a single medium (text) which requires the reader to relate the words to their experience.
Algorithmic construction isn't exclusive to machines. In 1943, poets James McAuley and Harold Stewart, dissatisfied with contemporary literary trends, crafted a series of nonsensical poems. The Ern Malley hoaxes involved constructing poems by opening the “Concise Oxford Dictionary, a Collected Shakespeare, and a Dictionary of Quotations" to a random page and "haphazardly" choosing and weaving words and phrases into a poem. McAuley and Stewart were attempting to parody modernist poetry by assembling senseless verses from arbitrary sources.
The Ern Malley edition of Angry PenguinsThese poems were written to be nonsensical, and yet they were celebrated within the literary community.
Both the Ern Malley hoax and machine-generated poetry share one major similarity: the assumption that there is an author who wanted to genuinely communicate something. The publishers of the poems, Angry Penguins, were enamored by the biography of the alleged "Ern Malley" and interpreted the nonsense poetry through his fictional struggles. A basic belief in talking with someone is that the other person is trying to convey a meaningful message. We treat people's words generously and assume that (at a minimum) they are attempting to make sense. If the words appear nonsensical, then we piece together meaning under the premise that they must've meant something and we need to figure that "something" out.
Patterns of language allow LLMs to create meaningful sentences. However, all meaning is actually produced by the human agent who is generously interpreting its statements and filling in the blanks with their own experience. We assume whatever we are communicating with is attempting to make sense, so we treat its statements with charity.